The AI training platform providing everything but AI!
AIchor allows LLM fine tuning and model training at scale while abstracting all the infrastructure and automating what is not AI related. AIchor platform is working either on-premise or in the cloud.
Why AIchor
AIchor's platform objective is to take advantage of the full power of high density CPU cores and advanced GPUs to distribute Machine Learning and Reinforcement Learning workloads at scale while abstracting the hardware and technical intricacies to AI Engineers and researchers.
Optimize the cost of infrastructure by leveraging our platform
Schedule model training and LLM fine tuning experiments
Rely on a sturdy solution with higher dataset durability
Have a seamless user experience and empower AI engineers
Seamless Distribution
A secure platform where Compute requirements specifications can be easily bootstrapped in a single file. Having one centralized access to the clusters.
GitOps Based
Researchers and Engineers can trigger experiments and trainings with a single command-line on their working branches. GitOps platform fosters collaboration and is efficient to Improve teamwork consolidation to address individual ML codes drifting.
Secure and easy to use
Workers are provisioned automatically based on the YAML description and the workload requirements taking into account the infrastructure availability.
How It Works
Get your workloads running on distributed resources in 4 steps
1 Provision your infrastructure
Import or create an engine from AIchor web interface where your workload will be running.
2 Plug your VCS
Connect your repository (Github, GitLab or Bitbucket) to integrate with AIchor.
3 Trigger your job
Request your resources and simply run your job.
4 Monitor your job
Follow your job's progress and monitor its logs, resources and costs.
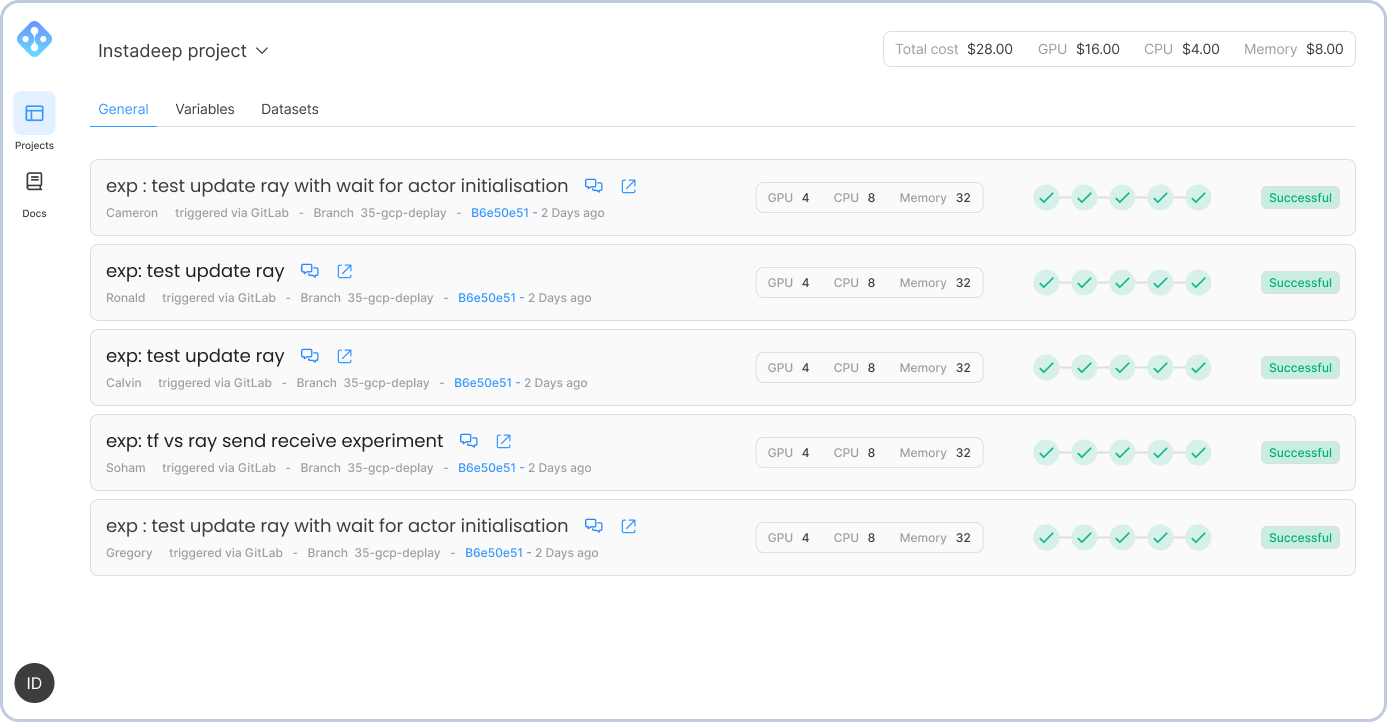
Workload Management
Logs management
Realtime logs being streamed and accessible via the UI
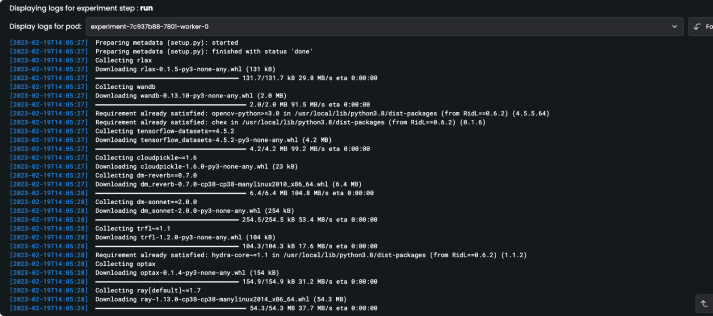
Resources
Users can monitor and manage their workloads from a web page, no need for ssh access. They can track compute costs easily by teams or projects from the user interface.
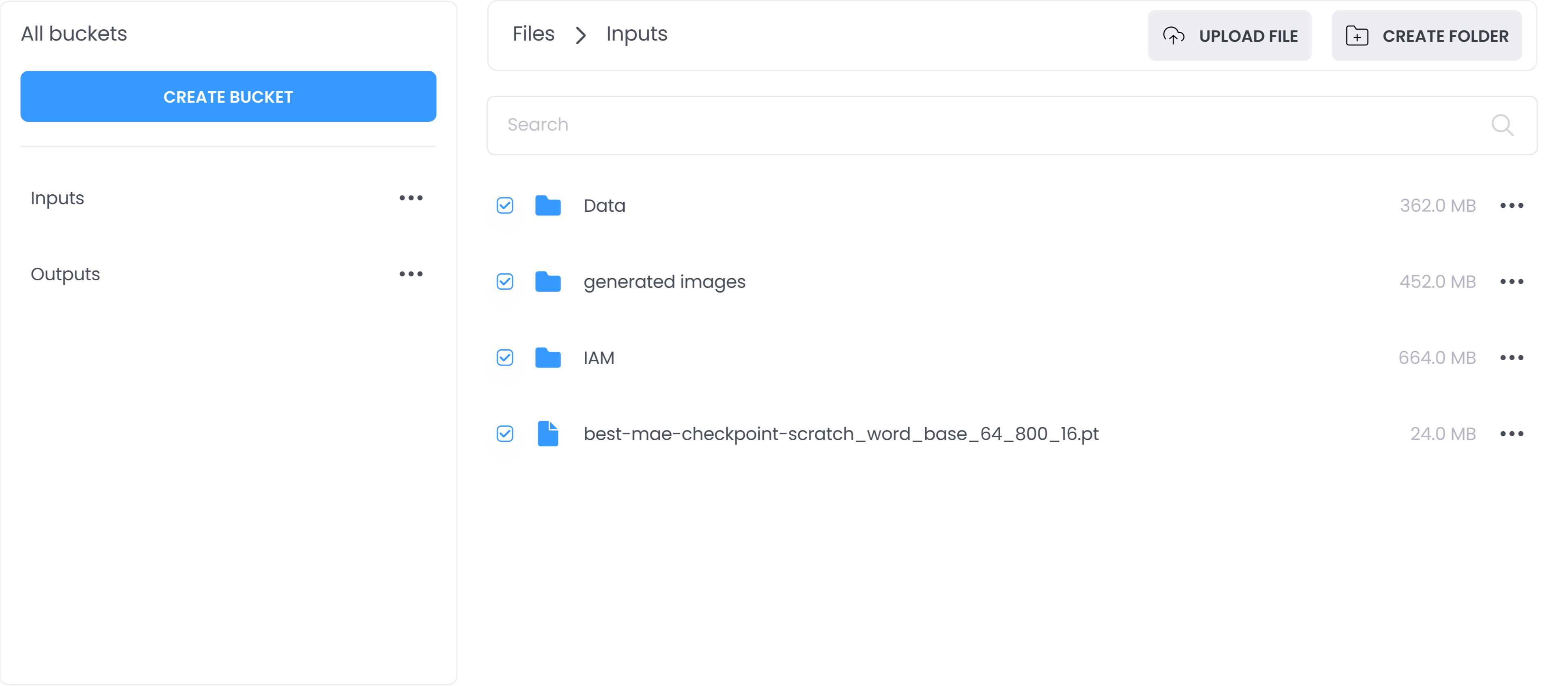
Storage
Ability to interact with input and output datasets.
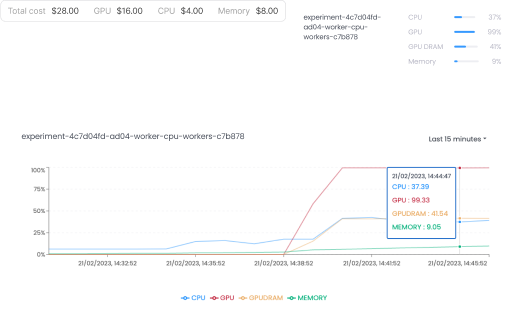
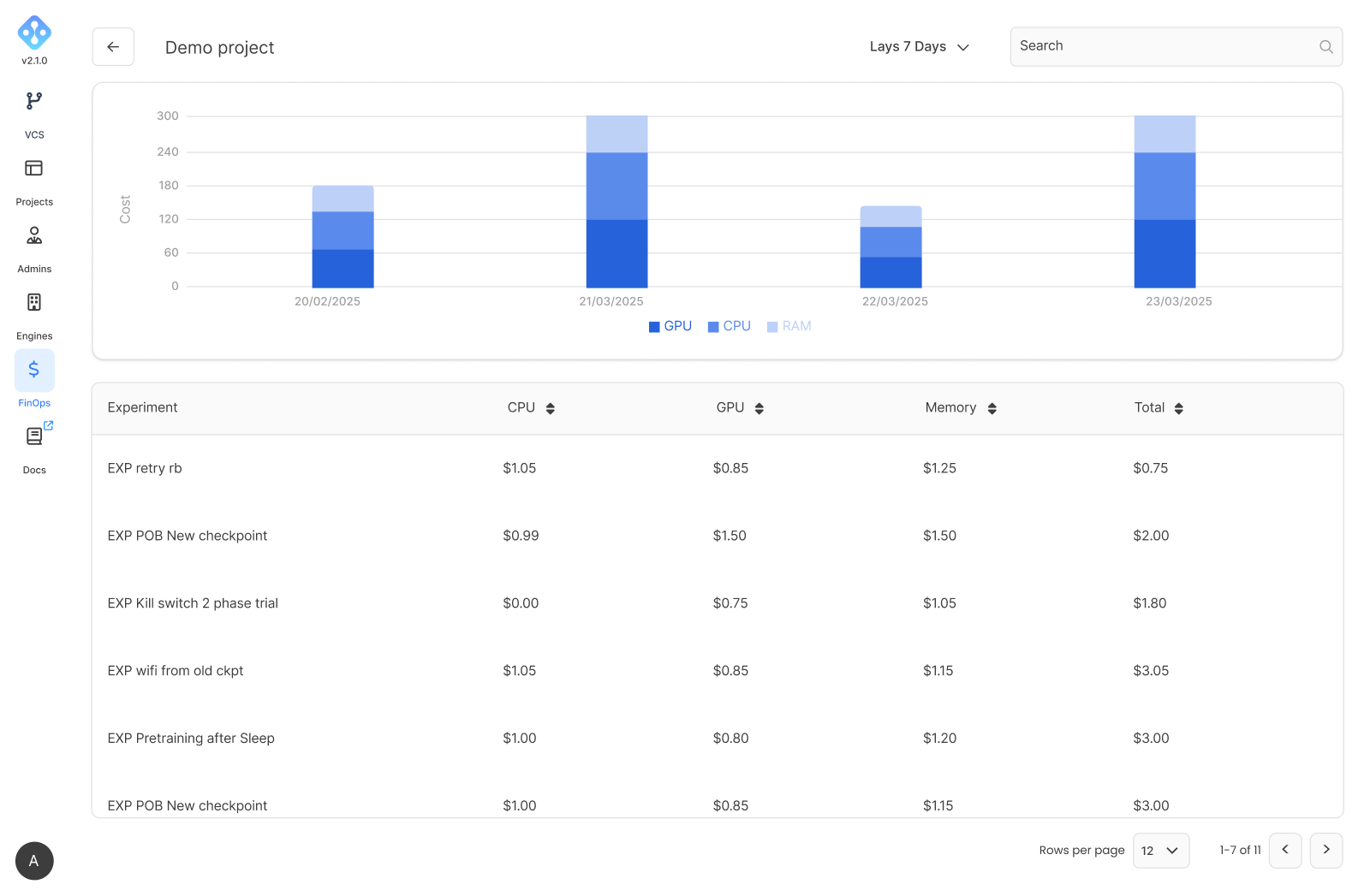
Cost Management
FinOps
Gain real-time visibility over your costs.
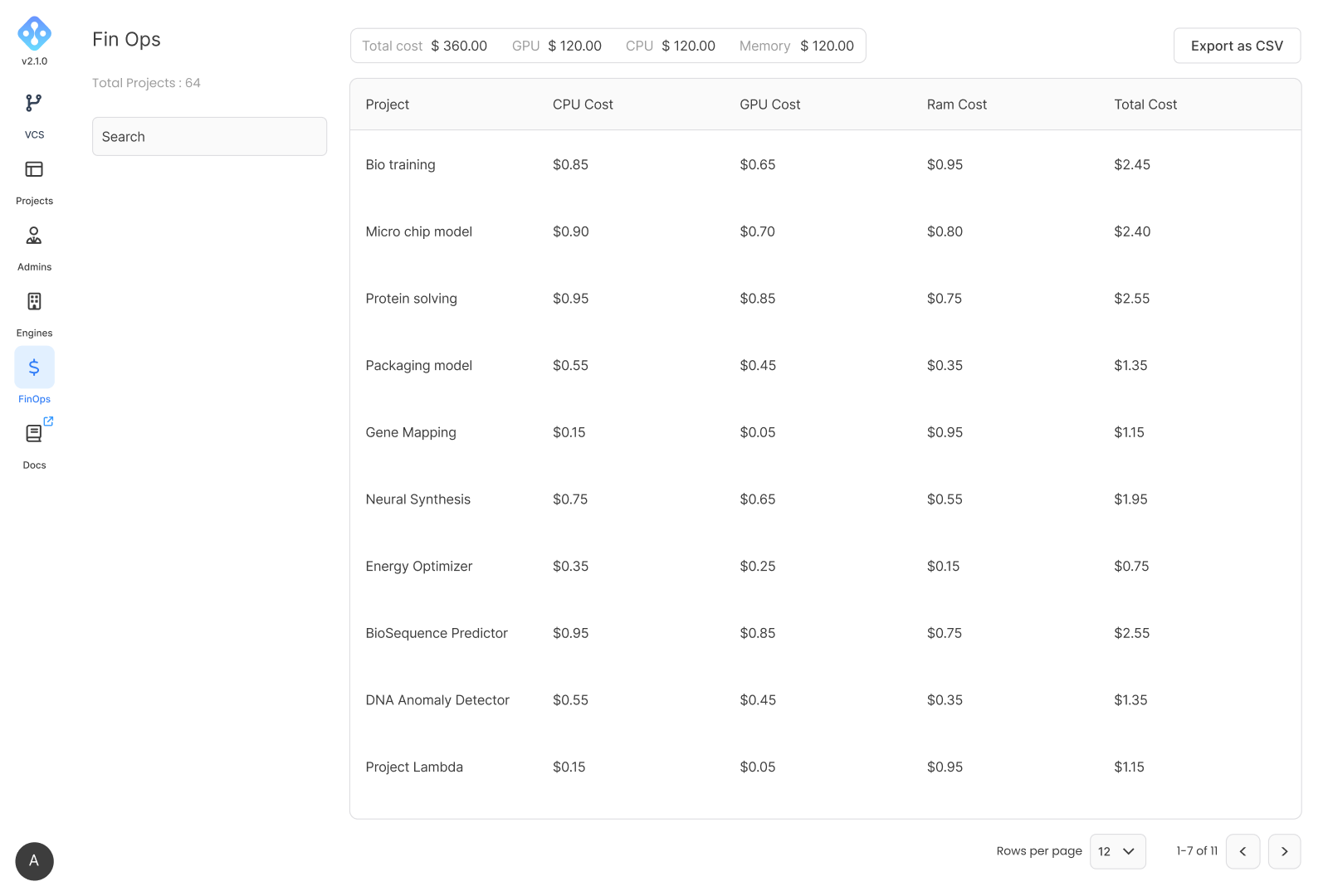
Customized dashboards
Keep cost control on your business
Working with big pre-trained models is challenging in terms of hardware requirements as we are all familiar with the CUDA OUT OF MEMORY error. We found AIchor to be the perfect solution that not only fixed all of that but also optimized the cost of infrastructure by using a containerized environment and engaging the A100s only when called. Thanks to AIchor, we now only need a data scientist with docker skills in order for us to iterate and improve our models.
Chehir Dhaouadi
Request a Demo
Test AIchor now with a Free demo.